
1. Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonomous Driving
Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonomous Driving
Multi-object tracking (MOT) with camera-LiDAR fusion demands accurate results of object detection, affinity computation and data association in real time. This paper presents an efficient multi-modal MOT framework with online joint detection and tracking s
ieeexplore.ieee.org
https://github.com/Kemo-Huang/JMODT
GitHub - Kemo-Huang/JMODT: Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonomous Driving
Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonomous Driving - GitHub - Kemo-Huang/JMODT: Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonom...
github.com

Contribution
- end-to-end joint detection and tracking
- develop robust affinity computation module
- develop data association module
Methods

1. calibrated sensor data가 RPN으로 입력으로 들어가 RoI와 그 영역에서의 multi-modal feature를 출력한다.
2. 병렬된 detection, correlation network가 feature를 사용하여 detection결과와 Re-ID affinity, start-end probability를 출력한다.
3. Re-ID affinity가 motion prediction과 match score ranking module을 통해 refine된다.
4. mixed-integer programming module이 data association을 수행한다.
5. track management를 수행한다.
2. Cross-Modal 3D Object Detection and Tracking for Auto-Driving
Cross-Modal 3D Object Detection and Tracking for Auto-Driving
Detecting and tracking objects in 3D scenes play crucial roles in autonomous driving. Successfully recognizing objects through space and time hinges on a strong detector and a reliable association scheme. Recent 3D detection and tracking approaches widely
ieeexplore.ieee.org
contribution
- cross-modal fusion(camera + LiDAR)
- association mechanism that exploit motion(position) and appearance

affinity를 appearance, position으로 구분하여 보완할 수 있도록 구성하였음.
Approach
A. Problem Context
object state s = (P,A)
P : (x, y, z, h, w, l, o) in 3D world coordinate
A : instance-aware appearance embedding
3D tracking을 위해 특정 sequence 동안 객체의 trajectory를 찾는 것을 목표로 한다.

B. Cross-Modal Fusion Scheme
1) Data Preprocessing
project LiDAR point into camera image plane + voxelize
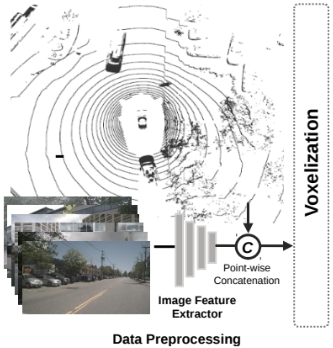
2) 3D Backbone
transfer vocel-wise feature into the BEV map

C. Joint Learning of Detection and Appearance Embedding
1) Detection Branch
2D RPN network + regression head
RPN : feature -> BEV feature map
regression head : detection result
2) Appearance Embedding Branch
2D RPN network + regression head
D. Tracking Association

position affinity와 appearance affinity를 계산함으로써 association을 수행한다.
filtering mechanism, rematching mechanism을 추가하여 새로운 tracking association pipeline 제안하였다.
appearance feature를 부정확한 matched pair를 filter하는데 사용하고, re-detected 객체를 filter하는데 사용하였다.
- position affinity
position affinity는 detection과 track 사이의 position distance Dp로 측정하였다.
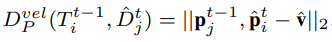
이전 시점에서의 Tracks과 현재 시점에서의 Detections에서 regressed velocity를 뺀 값을 이용해 Dp를 구한다.
즉, 여기서 prediction모델은 단순한 velocity model을 사용하였다고 볼 수 있다.
regressed velocity가 항상 가능한 것은 아닌데,(왜?)
이런 경우에는 kalman filter motion model을 사용하였다.
- appearance affinity
appearance affinity는 detection과 track 사이의 appearance distance Da로 측정하였다.
이전 시점에서의 Tracks에서 추출한 embedding feature와 현재 시점에서의 Detections에서 추출한 embedding feature 사이의 cosine distance를 계산하여 이를 Da로 사용하였다.
association은 두 단계로 진행된다.
1) position affinity에 대해 greedy bipartite matching를 수행하여 matched pairs를 구한다. 이 때, appearance affinity를 이용해 부정확한(position은 가깝지만 appearance가 다른) matched pair를 제거한다.
2) unmatched pairs(detections, tracks)를 대상으로 appearance affinity를 이용해 re-match를 수행한다.
3. Exploring Simple 3D Multi-Object Tracking for Autonomous Driving
ICCV 2021 Open Access Repository
Exploring Simple 3D Multi-Object Tracking for Autonomous Driving Chenxu Luo, Xiaodong Yang, Alan Yuille; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10488-10497 Abstract 3D multi-object tracking in LiDAR point
openaccess.thecvf.com
https://github.com/qcraftai/simtrack
GitHub - qcraftai/simtrack: Exploring Simple 3D Multi-Object Tracking for Autonomous Driving (ICCV 2021)
Exploring Simple 3D Multi-Object Tracking for Autonomous Driving (ICCV 2021) - GitHub - qcraftai/simtrack: Exploring Simple 3D Multi-Object Tracking for Autonomous Driving (ICCV 2021)
github.com

Contribution
- flexible to pillar or voxel backbone network
- hybrid-time centerness map을 제안하여 추가적인 heuristic matching 없이 current detection과 이전의 track을 link하였다.
- motion updating branch 제안(prediction)
- map을 사용하기 때문에 적정 threshold 값으로 new-born, dead track 관리 가능하여 life management 불필요
Method
Hybrid-Time Centerness Map
t-1, t의 input을 받아 각 object의 target centerness map을 생성한다.
이 때, target heatmap은 세 가지 경우로 나뉜다.
1) t-1, t에서 모두 존재 : t-1에서의 center location을 heatmap으로 사용한다.
2) t-1에서만 존재(dead) : target heatmap을 부여하지 않는다.
3) t에서만 존재(new-born) : t에서의 center location을 heatmap으로 사용한다.
이 hybrid-centerness map을 활용함으로써 추가적인 matching을 사용하지 않고, life management를 할 필요가 없다.
Motion Updating Branch
inference를 위해 객체의 현재 위치를 파악해야 한다.
∆u, ∆v = u(t) - u(t-1), v(t) - v(t-1) 로 motion을 사용하여 heatmap을 update한다.
Other Regression Branch
motion 정보(x, y) 뿐 아니라 z, h, w, l, o와 같은 다른 3D object properties를 regress한다.
Online Inference

시점 t 일 때, t-1 centerness map에 대해 Ego-motion을 사용하여 current vehicle coordinate로 변환
current hybrid-centerness map Yt와 Zt-1을 average하고, Yt에서 새로운 객체는 그 중심으로 초기화한다.
Yt에서 threshold를 넘지 못한 값은 dead로 간주하여 삭제한다.
이후, predicted motion map Mt를 사용하여 update하여 최종적으로 current locations of tracked objects 얻는다.
4. 3DMODT: Attention-Guided Affinities for Joint Detection & Tracking in 3D Point Clouds
3DMODT: Attention-Guided Affinities for Joint Detection & Tracking in 3D Point Clouds
We propose a method for joint detection and tracking of multiple objects in 3D point clouds, a task conventionally treated as a two-step process comprising object detection followed by data association. Our method embeds both steps into a single end-to-end
ieeexplore.ieee.org
Contribution
- 3D JDT method
- end-to-end network that directly processes raw point clouds to produce multiple object tracks
- attention-based refinement module
Method

A. Feature Extraction
t-2, t-1, t시점에서 point cloud를 입력으로 transformer encoder에서 feature tokens를 각각 추출한다.
B. Attention-Guided Affinity Refinement
Affinity Estimation
cosine similarity로 계산하여 affinity matrix 생성.
t-2 ~ t-1 -> A(t-1)
t-1 ~ t -> A(t)
Affinity Refinement
self-attention과 cross-attention을 수행하여 refinement
self-attention : affinity matrix내에서 잘못된 대응을 방지하기 위함
cross-attention : 연속된 affinity matrix에서 잘못된 대응을 방지하기 위함
C. Tracking Offset and 3D Bounding Box Prediction
tracking offset과 3D box를 생성함.
tracking offset : spatio-temporal 변위(시점 간)
D. Tracklet Generation
시점 t를 기준으로 t-1에서 tracking offset 내에 존재하는 box를 찾는다.
이 때, 일치하지 않는 경우에는 cosine affinity를 계산하여 높은 기준으로 연관시킨다.
마지막으로 일치하지 않는 box는 새로운 tracklet으로 등록한다.
5. CenterTube: Tracking multiple 3D objects with 4D tubelets in dynamic point clouds
CenterTube: Tracking Multiple 3D Objects with 4D Tubelets in Dynamic Point Clouds
3D Multi-Object Tracking (MOT) in dynamic point cloud sequences is a fundamental research problem for several downstream tasks such as motion planning and action recognition. Existing methods usually rely on the traditional tracking-by-detection (TBD) para
ieeexplore.ieee.org
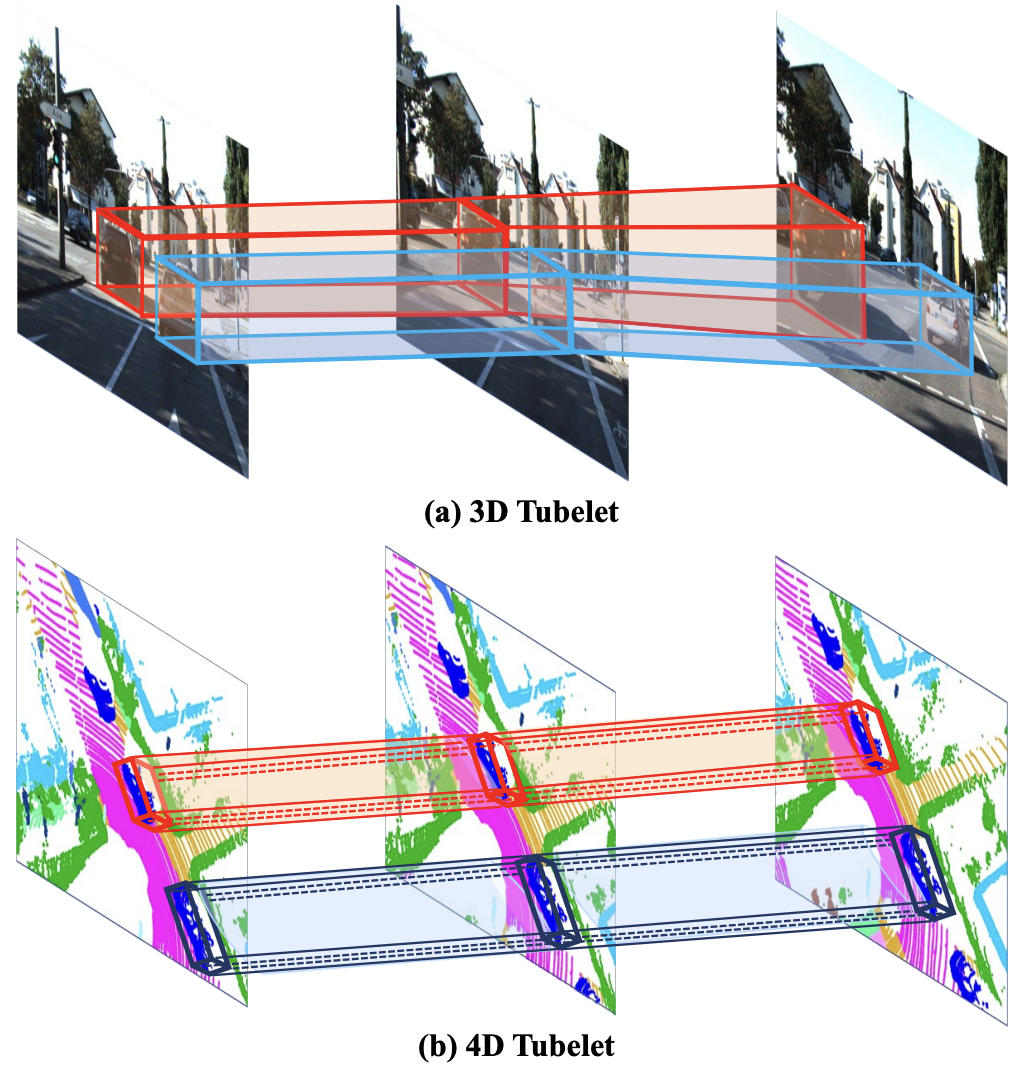
The key to our approach is to formulate the problem of multiple object trajectory predictions as 4D tubelet detections.
Methods
A. From 3D Dynamic Point Clouds to 4D Tubelets
linear spline interpolation : 4D tubelet is simply determined by two 3D boxes, the start box Bs and the end box Be.
The rest of boxes {Bs+1, Bs+2, ..., Be−1} can be restored through interpolation between Bs and Be.
3D box를 시간적으로 쌓아 4D Tubelet을 만들고, 시간 t를 짧게 가져가 선형적으로 보간하여 모든 sequence가 아닌 start와 end만 사용하였다.
현재 프레임에서의 box를 end box로 사용하였다. 그 후, 3D IoU가 0이 될때까지 이전 프레임을 살펴보며 start box를 찾는다.(처음으로 3D IoU가 0이 되는 box)
3D box 크기는 프레임이 이동해도 어느정도 일관되기 때문에 중심점을 사용하여 궤적을 모델링하고 현재 프레임에서의 크기만 사용한다. 또한, 선형 움직임 가정으로 방향 또한 현재 프레임 값만 사용한다. 결과적으로 3D MOT는 4D tublet detection으로 간주할 수 있다.
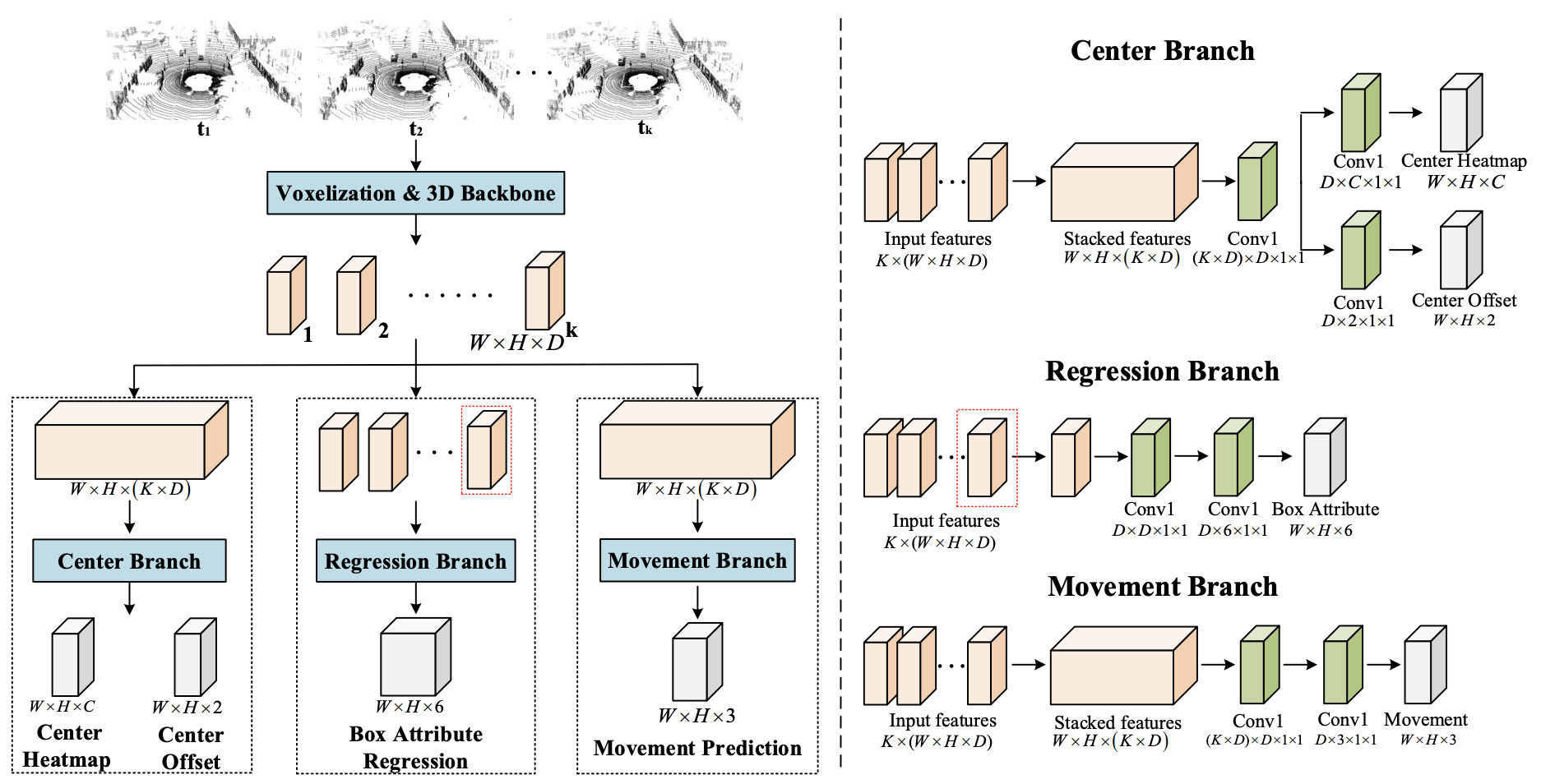
B. Network Architecture
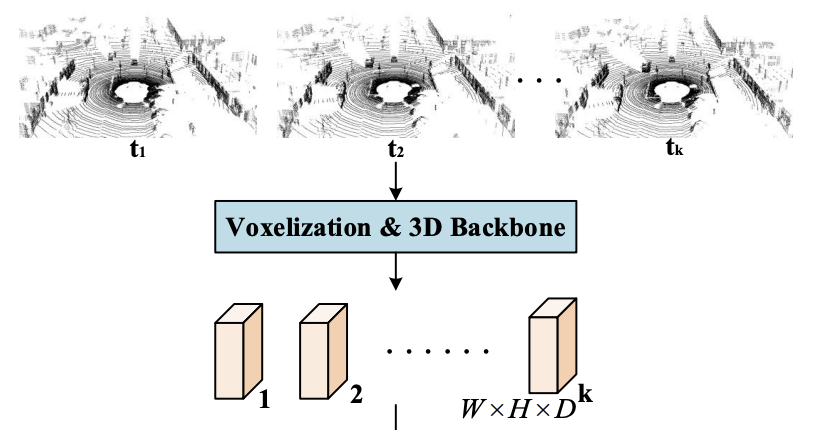
K 프레임을 갖는 클립을 입력으로 사용하고 추적을 위한 여러 개의 감지된 튜블릿을 생성한다.
우선, 입력 프레임을 현재 프레임에 등록한다. 그 후, PointPillars나 VoxelNet의 3D encoder로 feature를 추출한다.
이때, feature는 BEV로 표현하여 W와 H는 2D map 너비와 높이, D는 채널 수이다.
이후 세 개의 병렬 branch를 사용한다.
1) Center Branch
current frame에서의 object center 및 semantic 추정.
2) Regression Branch
size, height-above-ground, and orientation과 같은 shape attributes를 regress.
3) Movement Branch
current frame Be의 center point를 가지고 Bs의 offset을 예측.
위 3단계가 end-to-end로 학습된다.
'Paradigm' 카테고리의 다른 글
| Trajectory Prediction using Radar Data (0) | 2023.12.15 |
|---|---|
| 3D MOT에서 JDE 적용이 어려운 이유 (0) | 2023.11.26 |
| 센서 융합 기술의 현 주소 (0) | 2023.11.10 |