
Paper : https://arxiv.org/abs/2011.07491
Github : https://github.com/lilygeorgescu/AED-SSMTL
Anomaly Detection in Video via Self-Supervised and Multi-Task Learning
Anomaly detection in video is a challenging computer vision problem. Due to the lack of anomalous events at training time, anomaly detection requires the design of learning methods without full supervision. In this paper, we approach anomalous event detect
arxiv.org
Abstract
self-supervised + multi-task learning at object level
self-supervised task
- forward/backward moving object 에 대한 구분(discrimination)
- 연속적/간헐적인 프레임에서의 객체 구분
- 특정 객체 특징 정보 재구성
Multitask
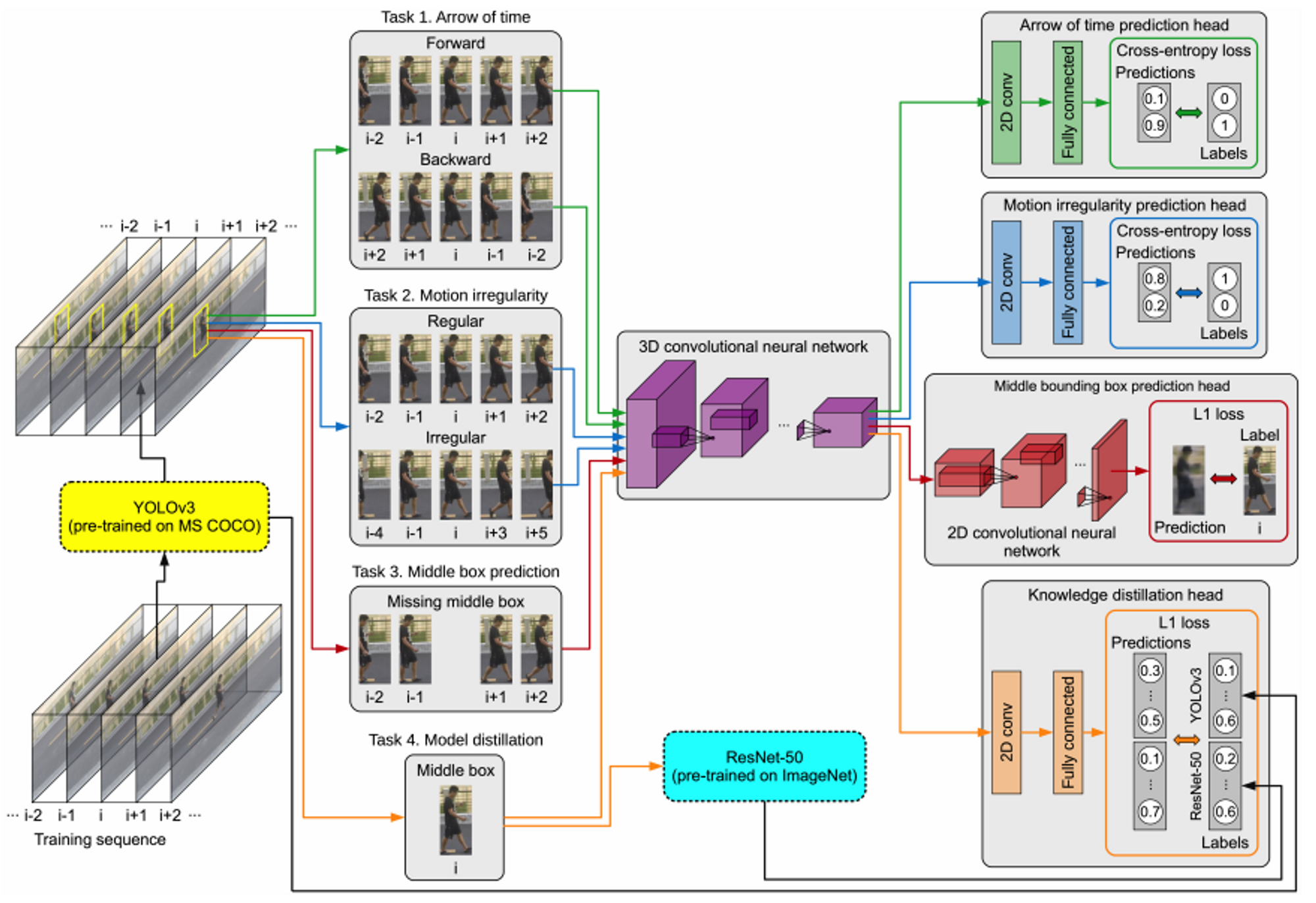
- Self-supervised
- Arrow of time → move backward 확률
- Motion irregularity → motion intermittent 확률
- Middle box prediction → MSE(reconstruction ↔ ground truth)
- knowledge distillation task
- Model distillation → class 확률 차이 (distillation ↔ yolov3)
→ 위 4개의 score를 평균내어 anomaly score로 사용함.
- AD 대용으로 learning the arrow of time 제안
- AD 대용으로 motion irregularity prediction 제안
- video AD 대용으로 model distillation 제안
- 3개의 self-supervised task 와 1개의 knowledge distillation task를 하나의 단일 모델로 결합하여 video Anomaly Detection을 수행하였음.
Method
Training
pre-trained detector 거쳐 frame i → object-centric temporal sequence 생성.(i-t,…,i-1,i,i+1,…,i+t)
이는 각 객체마다 i-t ~ i+t 까지의 bbox 데이터 묶음으로 볼 수 있다.
이 object-centric temporal sequence를 3D CNN에 input으로 넣게 된다.
tracking은 수행하지 않는다.
Inference
각 task에서 도출된 score를 평균 내 anomaly score를 뽑는다.
- arrow of time, motion irregularity → temporal sequence 가 backward 또는 intermittent(간헐적)일 확률
- middle frame prediction → difference between gt and reconstruct object.
- knowledge distillation → difference between the class probability YOLO and distillation branch.
inference시 ResNet50은 포함하지 않음.
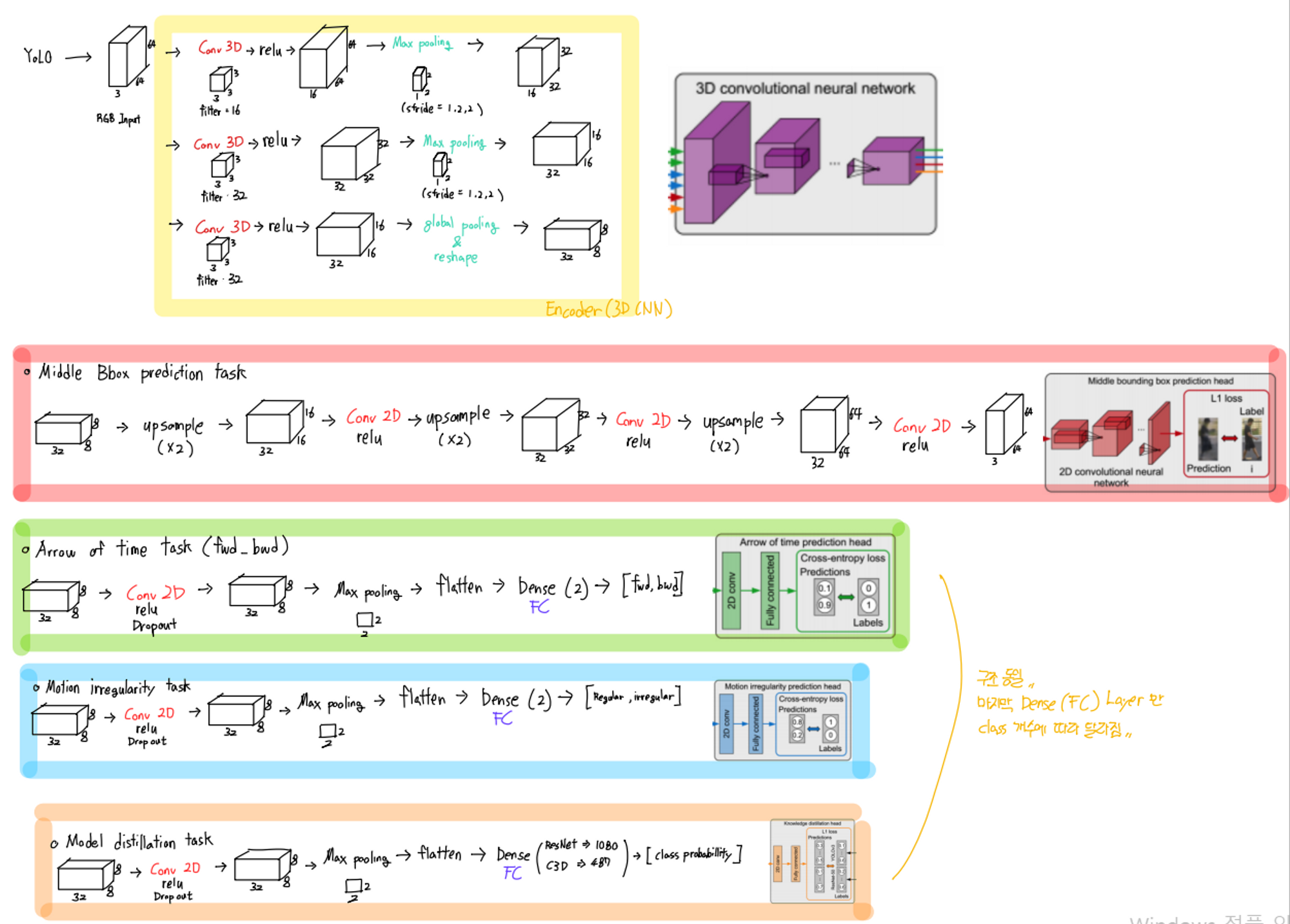
Neural Architecture
Multitask에 걸맞게 CNN의 width와 depth를 증가시켰다.
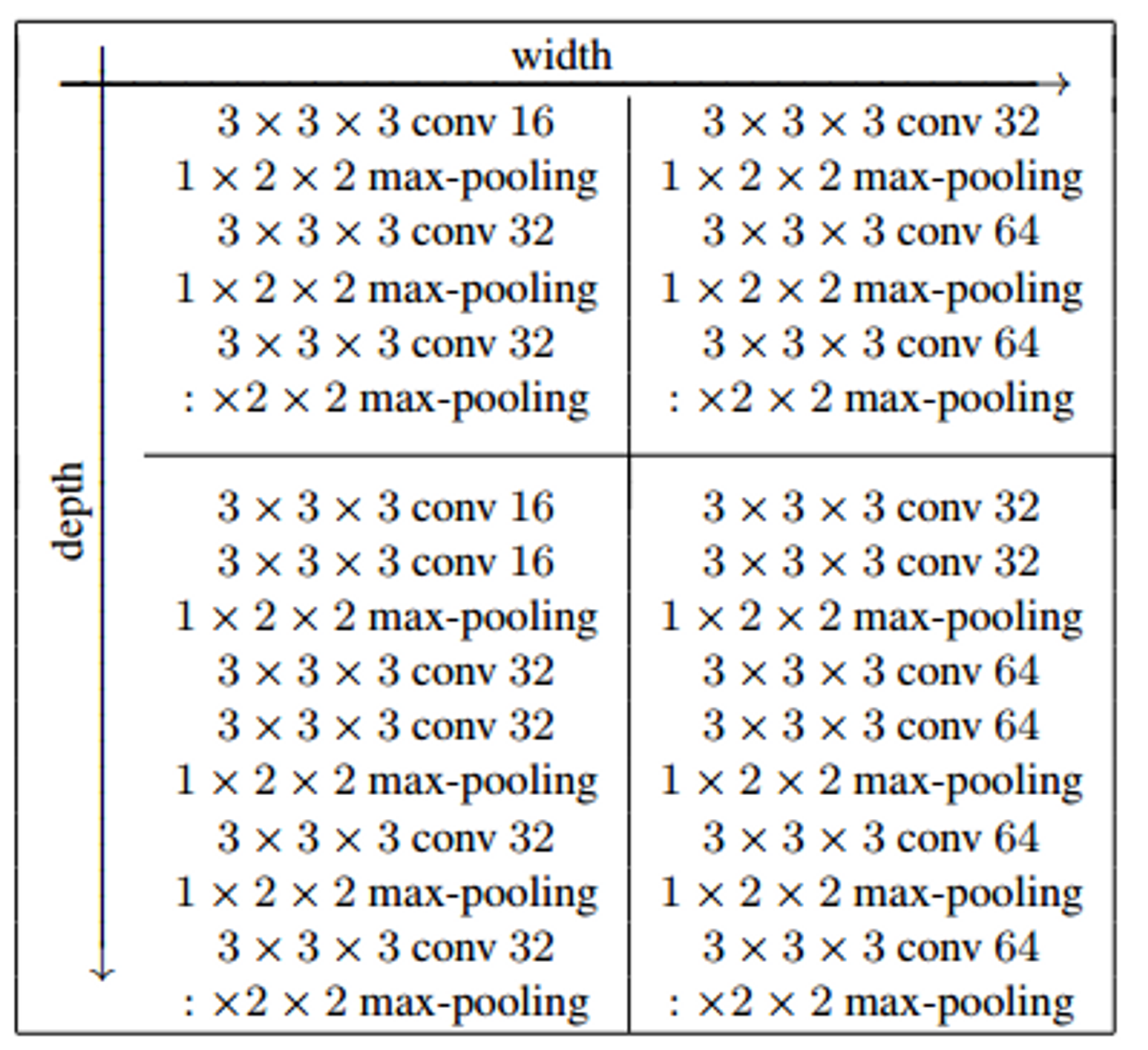
좌측 상단부터 shallow+narrow, shallow+wide, deep+narrow, deep+wide
각 CNN은 하나의 task 수행.
각각의 네트워크에서 RGB input size = 64 x 64 pixels.
이 3D CNN은 encoder 단계에서 사용함.
3D CNN 마지막 Layer에서 global-temporal pooling 사용하여 head 단계에서 2D CNN사용 가능.
decoder 단계에서는 2D CNN 사용.
이 때 각 upsampling과 conv layer는 3D CNN과 동일한 수로 이루어짐.
Proxy task and joint learning
task 1 : Arrow of time
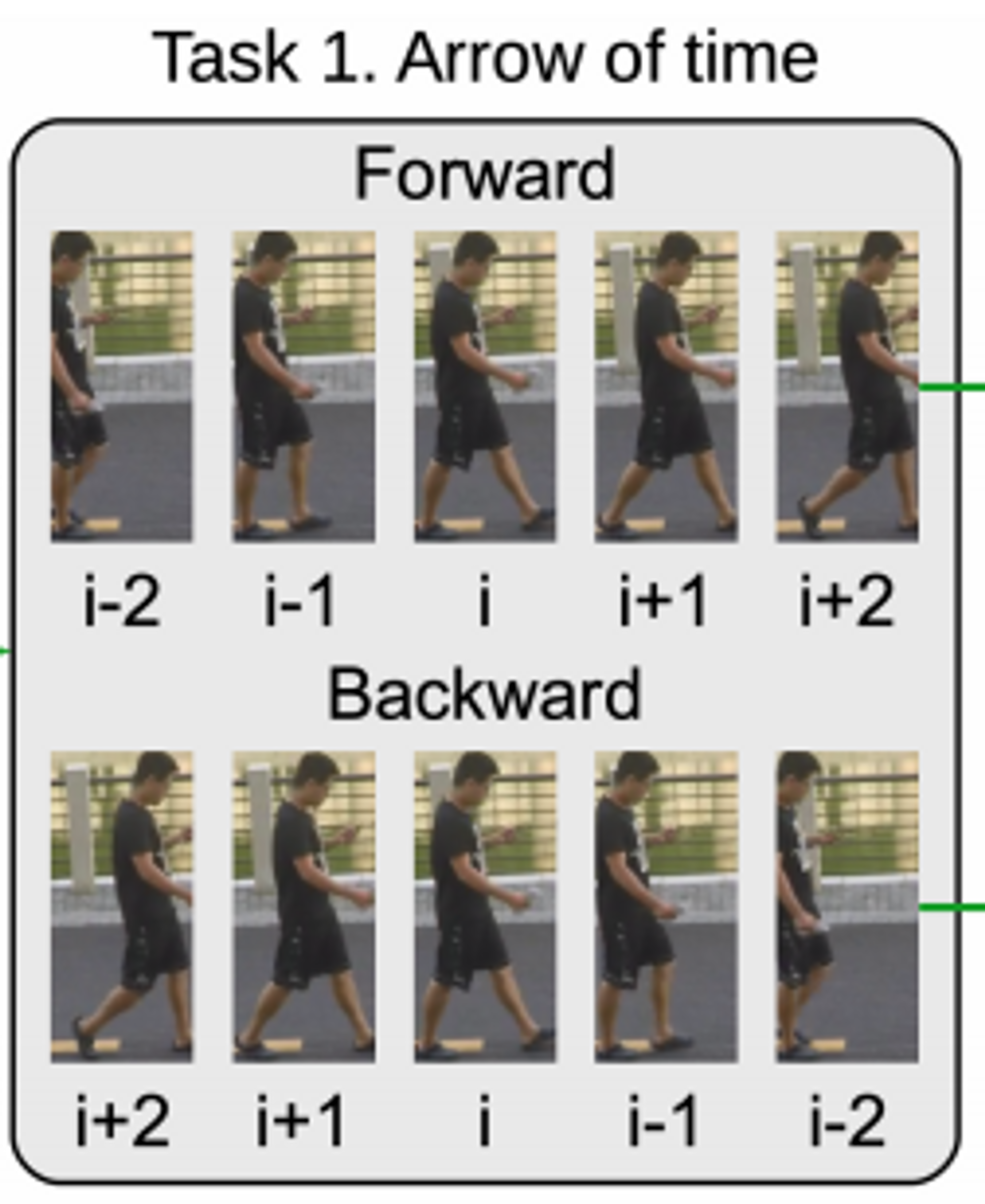
각 object centric sequence 마다 2개의 labeled training sample 생성.
- forward motion
- backward motion
→ anomalous motion일수록 예측 어려움.
Task 2 : Motion irregularity

각 object centric sequence 마다 2개의 labeled training sample 생성.
- consecutive
- intermittent(skip some frame)
→ intermittent object centric sequence 가 irregular motion으로 label됨.
Task 3 : Middle bounding box prediciton

normal video 로 학습시킨 모델에서 frame i 에 해당하는 middle bbox는 reconstruction된다.
이 때 anomalous object는 Loss가 클 것이다.
Task 4 : Model distillation
3D CNN에서 ResNet-50의 마지막 layer에서 나오는 feature를 예측하도록 학습한다.(pretrained on ImageNet)
3D CNN에서 YOLOv3에서 예측하는 class 확률을 예측하도록 학습한다.(pretrained on MS COCO)
즉, distillation 단계에서 모델은 teacher(ResNet-50, YOLOv3) 의 예측하는 행동을 학습한다.
inference 단계에서 abnormal 객체가 들어왔을 때 student와 teacher의 예측 값은 상이할 것이다.
3D CNN 을 공유하므로 joint된 loss를 사용하여 업데이트한다.
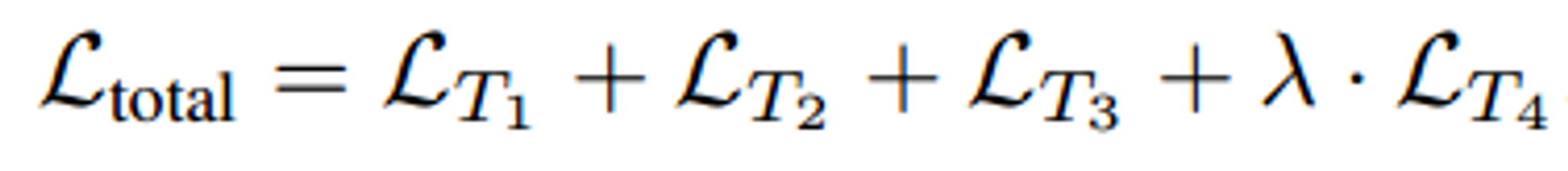
Inference
- probability of the temporal sequence to move backward as the anomaly score.
- probability of the gapless test sequence X to be intermittent as a good abnormality indicator.
- mean absolute error between the reconstructed and the ground-truth middle object as the anomaly score.
- absolute difference between the class probabilities. (predictor ↔ YOLOv3)