
https://arxiv.org/abs/2012.15460
TransTrack: Multiple Object Tracking with Transformer
In this work, we propose TransTrack, a simple but efficient scheme to solve the multiple object tracking problems. TransTrack leverages the transformer architecture, which is an attention-based query-key mechanism. It applies object features from the previ
arxiv.org
이번에 리뷰할 논문은 2D MOT 논문으로 transformer를 이용한 Joint Detection and Tracking 방식을 사용하였다.
Introduction
object tracking task는 크게 SOT(Single Object Tracking), MOT(Multi Object Tracking)으로 분류할 수 있다.
MOT에서 기존 연구들은 detection과 re-identification을 따로 수행하였고(Tracking by Detection), 서로 영향을 끼치지 못하였다.
같은 객체는 서로 다른 프레임이라도 비슷한 feature를 가진다는 가정에 근거하여 Query-Key mechanism이 SOT에서 발전되었다. 하지만 이런 방식은 새로 등장하는 객체에 해당하는 feature를 대응하기 어렵기 때문에 MOT에 적용하기에 적합하지 않다. 따라서 새로 등장하는 객체를 놓치지 않으면서(detection) 이전에 탐지되었던 객체들은 현재와 연관지을 수 있는(propagation) 방안을 생각해야 한다.
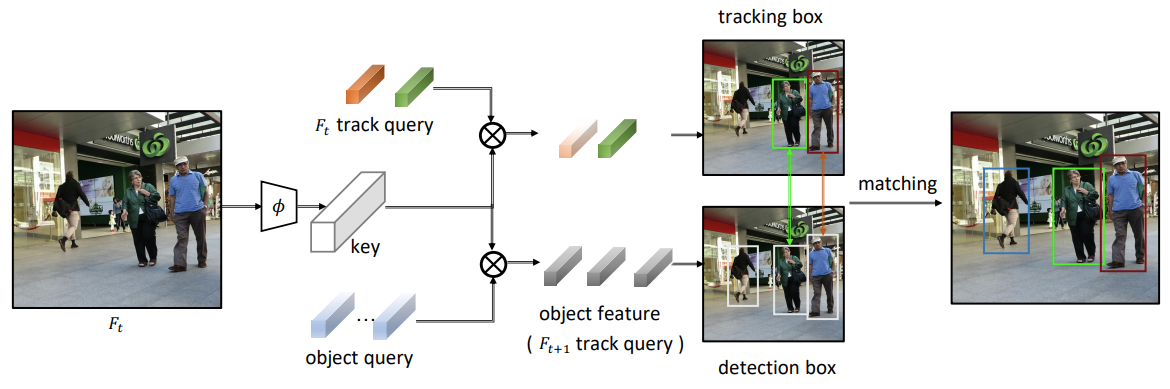
본 논문에서는 transformer decoder로 부터 학습하는 object query와 이전 프레임에서 객체의 feature로 부터 생성된 track query를 사용하여 문제에 접근하였다.
동일한 transformer decoder 구조를 사용하여 두 개의 query를 입력으로 detection box와 tracking box를 출력한다.
이후, IoU를 기준으로 매칭을 수행한다.
Method
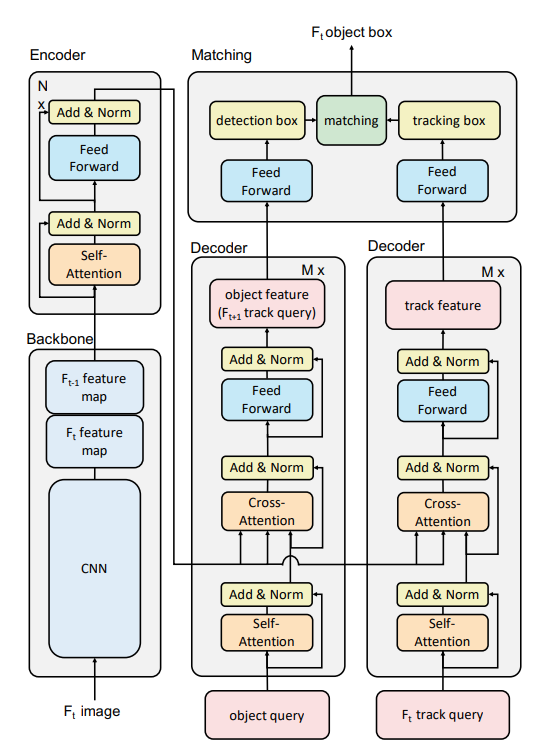
TransTrack은 transformer를 기반으로 하여 encoder-decoder 구조를 가진다.
encoder에서는 key를 생성하고, decoder에서는 task-specific query를 입력으로 하여 attention연산을 수행한다.
Encoder
두 연속적인 프레임에서의 feature map을 입력으로 한다.(by ResNet-50)
현재 프레임에서 추출된 feature map은 다음 스텝에서 재사용된다.(연산량 감소)
최종적으로 출력되는 feature map은 decoder에서 attention연산의 key로 사용된다.
Decoder
두 개의 병렬된 decoder는 각각 object detection과 object propagation을 수행하도록 설계되었다.
Object Detection
DETR의 구조를 따라 learned object query를 사용한다.
encoder에서 생성된 global feature maps을 key로 삼아 query가 object에 해당하는 object feature로 된다.
이후, feed forward를 거쳐 detection box를 출력한다.
즉, 이 단계는 현재 프레임에서 수행되는 object detection으로 볼 수 있다.
Object Propagation
이전 스텝에서 detect된 객체들의 object feature를 track query로 삼아 현재 시점에서 객체의 위치 예측을 수행한다.
object detection을 수행하는 decoder의 구조와 동일하다.
즉, 이 단계는 이전 시점의 객체 정보로 현재 시점에서의 객체 위치를 예측하는 prediction으로 볼 수 있다.
Matching
decoder에서 출력한 detection box, tracking box를 매칭하여 최종적인 tracking result를 출력한다.
이때, Kuhn-Munkres(KM) algorithm(헝가리안 알고리즘)을 사용해 IoU를 기준으로 detection box를 tracking box에 매칭한다.
new-born : unmatched detection box는 새로운 tracklet을 만든다.
rebirth : unmatched tracking box는 'inactive'로 등록한 후 K번의 프레임 동안 보류한다.(K=32)
그렇다면, inactive로 등록된 tracklet도 계속 업데이트를 해주나? 위치를 업데이트 하지 않으면 의미가 없을텐데...
Training
tracking box와 detection box는 모두 동일한 이미지 프레임에서의 prediction으로 볼 수 있다. 따라서 동일한 loss를 사용해 동시에 두 개의 decoder를 학습할 수 있다.

$L_(cls)$ : 객체의 class와 관련된 focal loss
$L_(L1)$ : predicted box의 center, h, w와 gt와의 L1 loss
$L_(giou)$ : predicted box의 center, h, w와 gt와의 generalized IoU loss
Results
