
ICCV 2021 Open Access Repository
Exploring Simple 3D Multi-Object Tracking for Autonomous Driving Chenxu Luo, Xiaodong Yang, Alan Yuille; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10488-10497 Abstract 3D multi-object tracking in LiDAR point
openaccess.thecvf.com
이번에 리뷰할 논문은 JDT(Joint Detection and Tracking) 기반의 LiDAR 3D MOT(Multi Object Tracking) 논문이다.
21년도에 나온 논문으로 성능이 현재 뛰어난 편은 아니지만, point cloud data만으로 JDT를 구현한 논문이 많지 않고(주로 카메라를 이용) 그 중에서도 코드를 제공하기 때문에 리뷰하게 되었다.
Introduction
기존 3D MOT연구들은 heuristic한 매칭 알고리즘에 의존하는 TBD(Tracking-By-Detection)방식을 사용한다.
이들은 주로 association 단계를 이분 매칭으로 규정하고, track과 새로운 detection간의 affinity matrix를 구하는데 집중한다.
여기서 저자가 말하는 heuristic rule은 다음과 같다.
1. association - 이분 매칭 알고리즘
2. life management - 카운트 방식
이러한 방식의 문제점은 다양한 변화에 적응하지 못하고, 하나하나 조정해줘야 한다는 점이다. 즉, 새로운 시나리오에 대응하지 못 한다.
본 논문의 contribution은 다음과 같다.(heuristic한 부분을 대체한 것을 가장 강조한다.)
1. pillar나 voxel 형태 모두 사용이 가능하다.
2. hybrid-time centerness map(period중 객체가 처음 등장한 위치 표현) 제안 -> association과정에서 추가적인 매칭이 필요없음
3. motion update branch를 새로 제안하였다.
4. confidence thresholding으로 life management를 대체하였다.
Methods
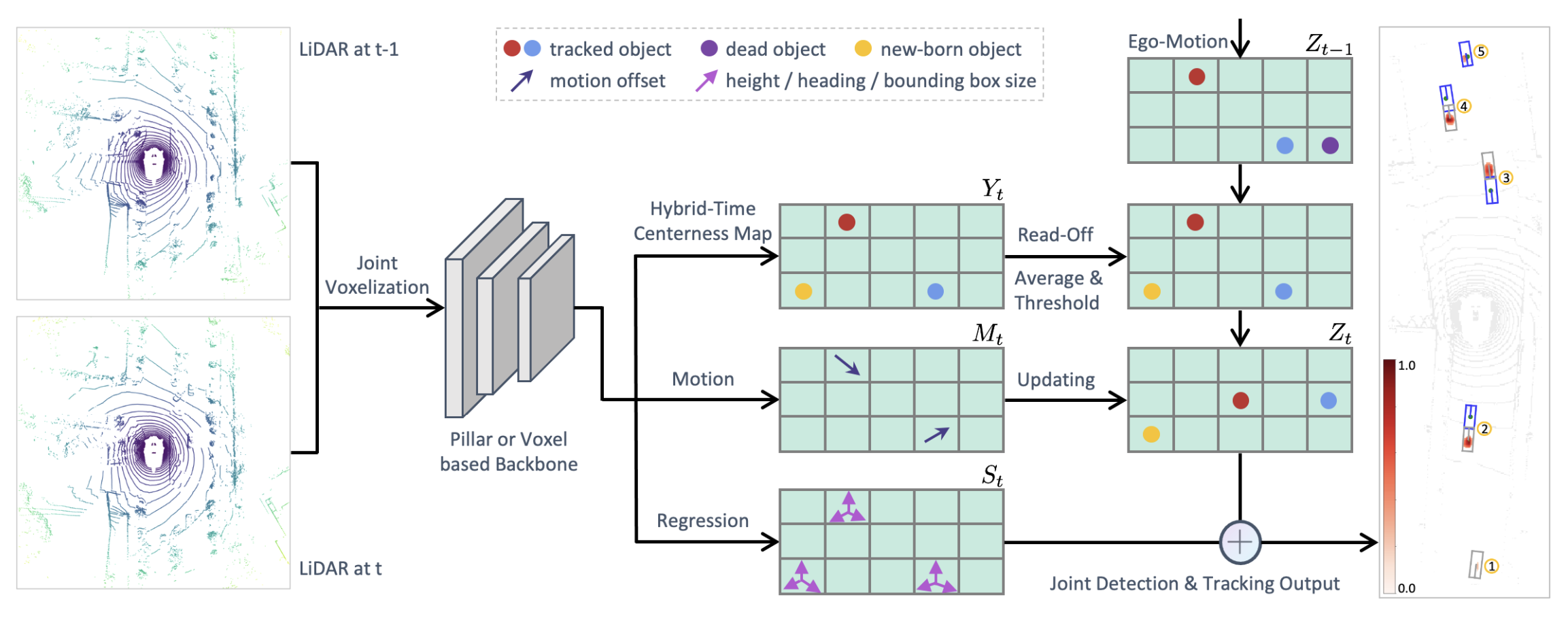
3D Object Detection
1. point cloud에 대해 voxelize
2. PointNet으로 feature 추출
3. Conv로 BEV feature 추출
4. head에서 각 객체를 centerness map상에서 center location으로 표현
학습 시, 실제 객체의 center를 중심으로 2D Gaussian heatmap을 생성하여 gt로 사용
Input
point cloud data $P^t=\{(x,y,z,r,\Delta t)\}$ snippet(sweeps 묶음)
이 때 snippet은 연속적인 2 sweeps으로 구성.(t-1, t)
Backbone
PointPillar나 VoxelNet 모두 사용이 가능하다.
Hybrid-Time Centerness Map
object가 snippet 내에서 처음 등장한 위치(중심)로 객체를 표현한다.
target heatmap을 생성하는 과정은 다음과 같다.
1. t-1, t 프레임에서 모두 존재하는 객체는 t-1에서의 위치로 target heatmap 할당
2. t-1 프레임에서만 존재하는 객체는 negative sample로 간주하고 heatmap 할당하지 않음
3. t 프레임에서만 존재하는 객체는 그 위치를 target heatmap으로 할당
이를 통해 얻는 효과는 다음과 같다.
1. 같은 위치의 heatmap 상에서 이전 프레임에서 기록된 ID정보를 읽어옴으로써 간단하게 매칭 가능
2. confidence thresholding으로 간단하게 life management 수행
Motion Updating Branch
online tracking을 수행하기 위해 객체의 현재 위치를 얻을 필요가 있다. (처음 등장한 위치를 사용하므로)
따라서 2 sweeps간의 offset을 추정한다. $(\Delta u, \Delta v)=(u_t - u_{t-1}, v_t - v_{t-1})$
여기서 $(u, v)$는 object center coordinate이다.
이 motion offset을 사용하여 updated centerness map을 얻게 된다.
이전의 연구들은 motion 정보를 주로 매칭에 도움이 되는 용도로 사용하였다. 즉, 프레임 간 객체를 연결하는 다리 역할만을 하였다.
하지만, 본 논문에서 motion 정보는 tracking output에 직접적으로 기여한다.
그래서 motion estimation을 어떻게 하는데?
Other Regression Branch
3D Object Detection 단계에서 motion 정보 뿐 아니라, height, box size, heading과 같은 정보도 추출한다.
이러한 정보는 motion 정보와 함께 tracking output을 도출하는데 사용된다.
Loss Function
Hybrid-Time Centerness map을 학습하는데 focal-loss를 사용하였다.
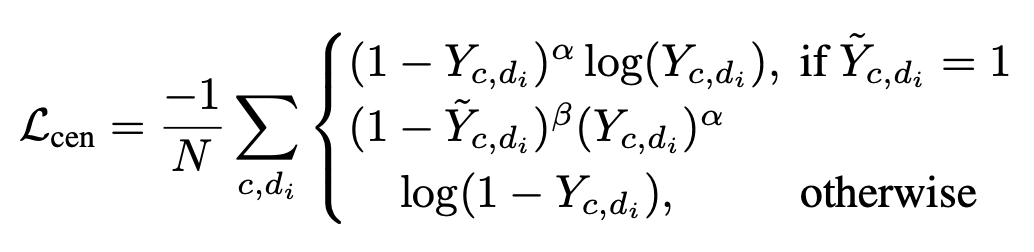
이해 안감. 코드 봐야 이해갈 듯
Motion과 Regression은 모두 L1-loss로 학습하였다.

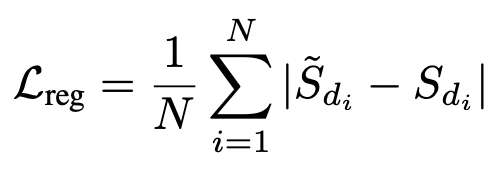

Online Inference
updated centerness map은 center of location, tracking ID, confidence score를 기록한다.
이 때 tracking ID는 object center location에 위치한다. (이게 무슨..?)
맨 처음의 경우
1개의 sweep만 입력으로 받아 detection을 수행하고 updated centerness map $Z_0$를 초기화한다.
보통의 경우
현재 sweep(t)과 이전의 sweep(t-1)을 입력으로 받는다.
1. 이전 timestamp updated centerness map $Z_{t-1}$를 ego motion 정보를 사용해 현재 coordinate로 변환한다.
2. 현재 centerness map $Y_t$와 $Z_{t-1}$를 평균한다. (뭐를 평균하는 거지?)
3. threshold and NMS 수행
4. $Z_{t-1}$와 같은 위치에 tracking ID가 존재하면, $Y_t$로 읽어온다.
5. $Y_t$에서 나머지 object center에 대해 new track으로 등록한다.
6. motion 정보를 사용해 $Y_t$를 updated centerness map $Z_t$으로 만든다.
Results
